문서
원본 보기5 에스컬레이션
개요
에스컬레이션을 통해 알림 발송이나 원격 명령 실행을 위한 사용자 정의 시나리오를 만들 수 있습니다.
실제로 이는 다음을 의미합니다:
- 사용자는 새로운 문제에 대해 즉시 알림을 받을 수 있습니다.
- 문제가 해결될 때까지 알림을 반복할 수 있습니다.
- 알림 발송을 지연시킬 수 있습니다.
- 알림을 다른 "상위" 사용자 그룹으로 에스컬레이션할 수 있습니다.
- 원격 명령을 즉시 실행하거나 문제가 오랫동안 해결되지 않았을 때 실행할 수 있습니다.
액션은 에스컬레이션 단계를 기반으로 에스컬레이션됩니다. 각 단계는 시간 지속 시간을 가집니다.
기본 지속 시간과 개별 단계의 사용자 정의 지속 시간을 모두 정의할 수 있습니다. 하나의 에스컬레이션 단계의 최소 지속 시간은 60초입니다.
모든 단계에서 알림 발송이나 명령 실행과 같은 액션을 시작할 수 있습니다. 첫 번째 단계는 즉시 액션을 위한 것입니다. 액션을 지연시키려면 이후 단계에 할당할 수 있습니다. 각 단계마다 여러 액션을 정의할 수 있습니다.
에스컬레이션 단계의 수는 제한되지 않습니다.
에스컬레이션은 오퍼레이션 구성 시에 정의됩니다. 에스컬레이션은 문제 오퍼레이션에만 지원되며, 복구 오퍼레이션에는 지원되지 않습니다.
에스컬레이션 동작의 기타 측면
액션에 여러 에스컬레이션 단계가 포함된 경우 다른 상황에서 어떤 일이 발생하는지 살펴보겠습니다.
| 상황 | 동작 |
|---|---|
| 초기 문제 알림이 발송된 후 해당 호스트가 유지보수로 전환됨 | 액션 구성에서 억제된 문제에 대한 작업 일시 정지 설정에 따라, 나머지 모든 에스컬레이션 단계는 유지보수 기간으로 인한 지연과 함께 실행되거나 지연 없이 실행됩니다. 유지보수 기간은 오퍼레이션을 취소하지 않습니다. |
| 초기 알림이 발송된 후 시간 대역 액션 조건에 정의된 시간 기간이 종료됨 | 나머지 모든 에스컬레이션 단계가 실행됩니다. 시간 대역 조건은 오퍼레이션을 중단할 수 없으며, 액션이 시작되는/시작되지 않는 시점에 대한 효과가 있지 오퍼레이션에는 없습니다. |
| 유지보수 중에 문제가 시작되고 유지보수가 끝난 후에도 계속됨(해결되지 않음) | 액션 구성에서 억제된 문제에 대한 작업 일시 정지 설정에 따라, 모든 에스컬레이션 단계는 유지보수가 끝나는 순간부터 또는 즉시 실행됩니다. |
| 데이터 없음 유지보수 중에 문제가 시작되고 유지보수가 끝난 후에도 계속됨(해결되지 않음) | 모든 에스컬레이션 단계가 실행되기 전에 트리거가 발동될 때까지 기다려야 합니다. |
| 서로 다른 에스컬레이션이 연속적으로 발생하고 겹침 | 각각의 새로운 에스컬레이션 실행은 이전 에스컬레이션을 대체하지만, 이전 에스컬레이션에서 항상 실행되는 최소 하나의 에스컬레이션 단계는 유지됩니다. 이 동작은 트리거의 모든 문제 평가마다 생성되는 이벤트에 대한 액션과 관련이 있습니다. |
| 에스컬레이션이 진행 중일 때(메시지가 발송되는 중과 같이), 모든 유형의 이벤트를 기반으로: - 액션이 비활성화됨 트리거 이벤트를 기반으로: - 트리거가 비활성화됨 - 호스트 또는 아이템이 비활성화됨 트리거에 대한 내부 이벤트를 기반으로: - 트리거가 비활성화됨 아이템/저수준 발견 규칙에 대한 내부 이벤트를 기반으로: - 아이템이 비활성화됨 - 호스트가 비활성화됨 |
진행 중인 메시지가 발송되고 에스컬레이션에서 하나 더의 메시지가 발송됩니다. 후속 메시지는 메시지 본문의 시작 부분에 취소 텍스트(NOTE: Escalation canceled)와 이유가 포함됩니다(예: NOTE: Escalation canceled: action '<액션명>' disabled). 이렇게 하여 수신자는 에스컬레이션이 취소되고 더 이상 단계가 실행되지 않음을 알 수 있습니다. 이 메시지는 이전에 알림을 받은 모든 사람에게 발송됩니다. 취소 이유는 서버 로그 파일에도 기록됩니다(Debug Level 3=Warning부터). 오퍼레이션이 완료되었지만 복구 오퍼레이션이 구성되어 있고 아직 실행되지 않은 경우에도 Escalation canceled 메시지가 발송됩니다. |
| 에스컬레이션이 진행 중일 때(메시지가 발송되는 중과 같이) 액션이 삭제됨 | 더 이상 메시지가 발송되지 않습니다. 정보는 서버 로그 파일에 기록됩니다(Debug Level 3=Warning부터), 예: escalation canceled: action id:334 deleted |
에스컬레이션 예제
예제 1
"MySQL Administrators" 그룹에 30분마다 한 번씩(총 5회) 반복 알림을 발송합니다. 구성하려면:
- Operations 탭에서 Default operation step duration을 "30m"(30분)으로 설정합니다.
- 에스컬레이션 Steps를 "1"에서 "5"로 설정합니다.
- "MySQL Administrators" 그룹을 메시지 수신자로 선택합니다.
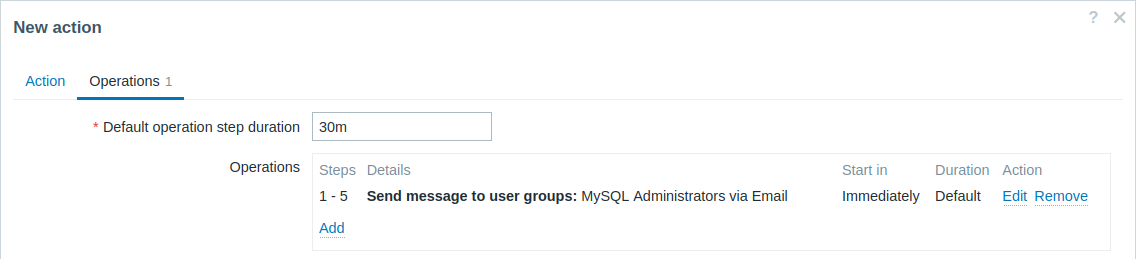
알림은 문제 시작 후 0:00, 0:30, 1:00, 1:30, 2:00 시간에 발송됩니다(물론 문제가 더 빨리 해결되지 않는 한).
문제가 해결되고 복구 메시지가 구성된 경우, 이 에스컬레이션 시나리오에서 최소 하나의 문제 메시지를 받은 사람들에게 발송됩니다.
활성 에스컬레이션을 생성한 트리거가 비활성화되면, Zabbix는 이미 알림을 받은 모든 사람에게 이에 대한 정보 메시지를 발송합니다.
예제 2
오래 지속된 문제에 대한 지연된 알림 발송. 구성하려면:
- Operations 탭에서 Default operation step duration을 "10h"(10시간)으로 설정합니다.
- 에스컬레이션 Steps를 "2"에서 "2"로 설정합니다.
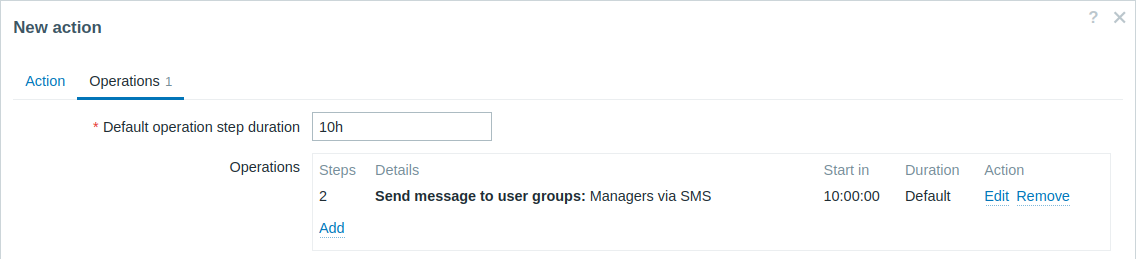
알림은 에스컬레이션 시나리오의 2단계, 즉 문제 시작 후 10시간에만 발송됩니다.
메시지 텍스트를 "문제가 10시간 이상 지속되고 있습니다"와 같이 사용자 정의할 수 있습니다.
예제 3
문제를 상사에게 에스컬레이션합니다.
위의 첫 번째 예제에서는 MySQL 관리자에게 주기적으로 메시지를 발송하도록 구성했습니다. 이 경우 관리자는 문제가 데이터베이스 매니저에게 에스컬레이션되기 전에 네 개의 메시지를 받습니다. 매니저는 문제가 아직 확인되지 않은 경우에만 메시지를 받으며, 아무도 작업하고 있지 않다고 가정합니다.
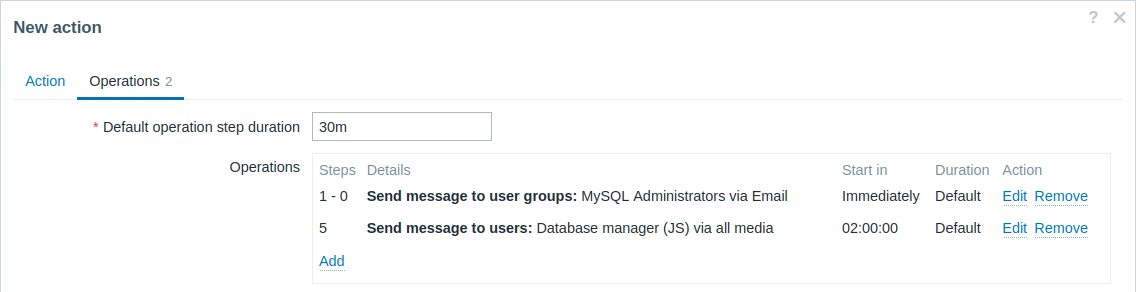
Operation 2의 세부사항:
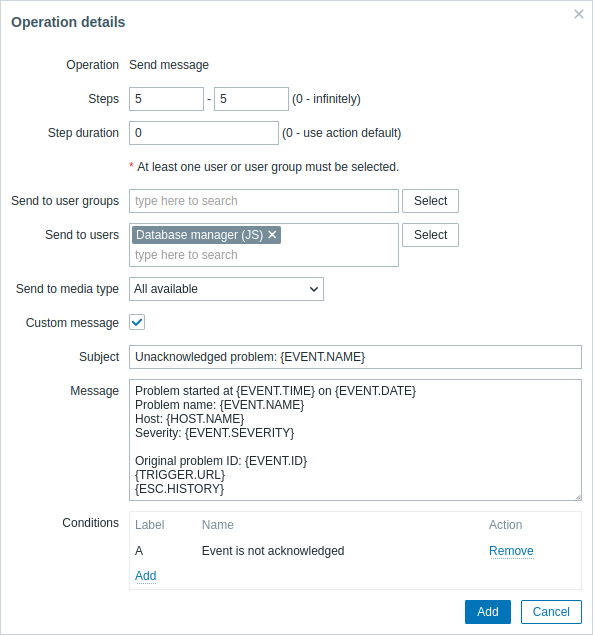
사용자 정의된 메시지에서 {ESC.HISTORY} 매크로의 사용에 주목하세요. 이 매크로에는 발송된 알림 및 실행된 명령 등 이 에스컬레이션에서 이전에 실행된 모든 단계에 대한 정보가 포함됩니다.
예제 4
더 복잡한 시나리오입니다. MySQL 관리자에게 여러 메시지를 보내고 매니저에게 에스컬레이션한 후, Zabbix는 MySQL 데이터베이스를 재시작하려고 시도합니다. 이는 문제가 2:30시간 동안 존재하고 확인되지 않은 경우에 발생합니다.
문제가 여전히 존재하면, 30분 후에 Zabbix는 모든 게스트 사용자에게 메시지를 발송합니다.
이것이 도움이 되지 않으면, 1시간 후에 Zabbix는 IPMI 명령을 사용하여 MySQL 데이터베이스가 있는 서버를 재부팅합니다(두 번째 원격 명령).
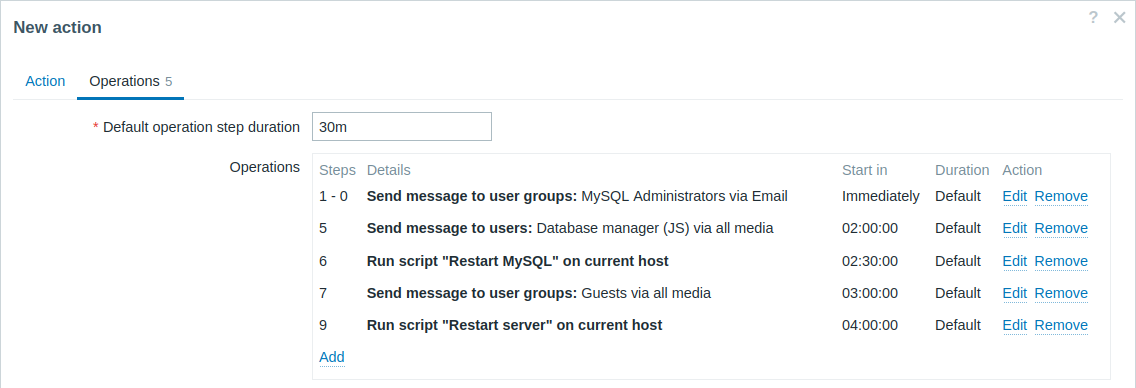
예제 5
겹치는 단계 범위와 사용자 정의 간격을 가진 여러 오퍼레이션이 있는 에스컬레이션입니다. 기본 오퍼레이션 단계 지속 시간은 30분입니다.
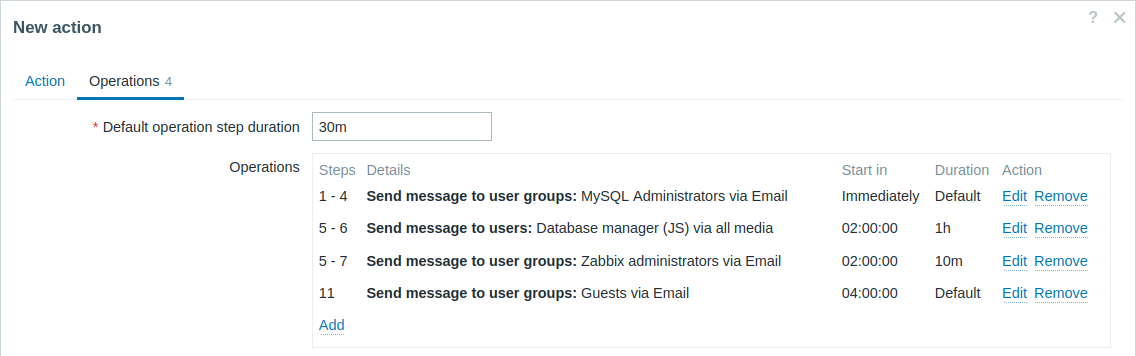
알림은 다음과 같이 발송됩니다:
- MySQL administrators에게 문제 시작 후 0:00, 0:30, 1:00, 1:30에 발송됩니다.
- Database manager에게 2:00과 2:10에 발송됩니다(후속 오퍼레이션에 정의된 더 짧은 사용자 정의 단계 지속 시간인 10분이 여기서 구성된 더 긴 단계 지속 시간인 1시간을 대체합니다. 오퍼레이션 세부사항에서 단계가 겹칠 때의 Step duration에 대해 설명된 대로).
- Zabbix administrators에게 문제 시작 후 2:00, 2:10, 2:20에 발송됩니다(사용자 정의 단계 지속 시간인 10분이 적용됨).
- 게스트 사용자에게 문제 시작 후 4:00에 발송됩니다(8단계와 11단계 사이에 기본 단계 지속 시간인 30분이 적용됨).